선정이유
최근 SNS 사용 증가로 개인정보 유출 문제가 심각해지는 것을 체감하면서, 이 논문이 제시한 '개인정보 유출위험도 측정 방법'이 매우 시의적절하다고 생각했다. 단순히 개인정보 노출 사실을 경고하는 것이 아니라, 유출 가능성과 위험도를 구체적으로 수치화하고 개인이 스스로 정보 노출 위험을 인식하고 관리할 수 있도록 유도하는 접근이 앞으로 개인정보 보호 대책 측면에서 좋은 것 같아 선정하게 되었다.
서론
최근 SNS(Social Network Service) 사용자가 급속히 증가하면서 개인정보 노출 및 유출 위험이 심각해지고 있다는 문제의식에서 출발한다. 특히 스마트폰 보급 확산에 따라 SNS 이용이 일상화되면서, 사용자의 개인정보가 손쉽게 노출되고 빠르게 전파될 수 있다는 위험성이 강조된다. 오프라인에서는 한정된 범위에서 관계가 맺어지지만, SNS에서는 공간적 제약 없이 정보가 빠르게 확산되기 때문에 개인정보 유출 시 그 피해가 광범위하게 확대될 수 있다. 이에 따라 사용자는 자신의 정보를 스스로 통제할 수 있는 자기정보관리통제권(Self-information control right)을 강화해야 할 필요가 있으며, 이를 위해 개인정보 유출 위험도를 측정하고 경각심을 높이는 방법을 제안하는 것이 본 논문의 주요 목적이다.
본론
1. SNS에서의 개인정보 침해문제와 대응방안
1.1 SNS에서의 개인정보 침해 문제
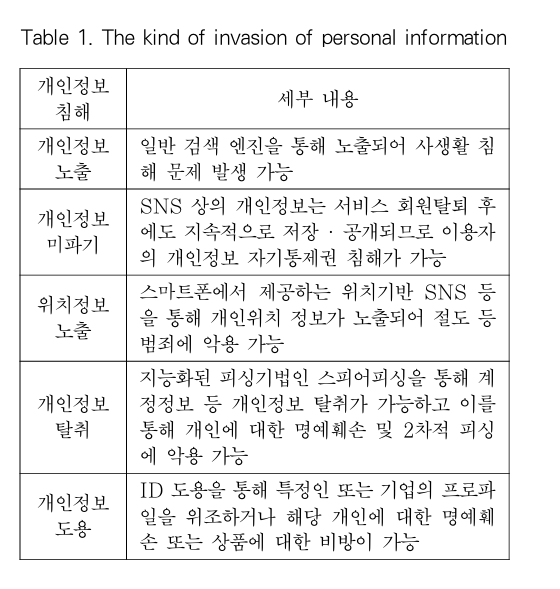
SNS에서는 사용자가 자발적으로 개인정보를 공개하는 경우가 많고, 그 과정에서 다양한 침해 사례가 발생하고 있다. 대표적인 사례로는 검색 엔진을 통한 정보 노출, 서비스 탈퇴 이후에도 삭제되지 않는 정보, 위치정보를 통한 범죄 악용, 스피어피싱을 통한 계정 탈취, ID 도용에 의한 명예훼손 등이 있다.
1.2 SNS 보안 위협에 따른 대응 방안
● 프로필 제한 방식
사용자의 관계 정보를 최소한만 공개하여 개인정보 노출을 억제하는 방법이다. 대표적으로 '집합 교차법'을 사용하여 공통 관심사를 기반으로만 관계를 형성한다.
한계점: 여전히 유출 위험 존재
● 보안 정책 방식
사용자가 직접 데이터 접근 권한을 설정하는 방법이다. P3P, EPAL, XACML 과 같은 정책 언어를 통해 유연한 접근 통제를 지원한다.
한계점: 사용자가 위험 수준을 명확히 인식하지 못한 채 설정해야 함
1.3 개인정보 유출 시 기존의 위험도 산정 방법
● 개인정보 영향평가(PIA)
새로운 정보 시스템 도입이나 기존 시스템의 중대한 변경 시 개인정보에 미치는 영향을 사전에 조사 예측 검토 하여 개선방안을 마련하는 체계적인 절차이다. 개인정보 조합 수준에 따라 자산가치를 평가하고 발생가능성과 법적 준거성과 결합해 최종 위험도를 합산하는 방식으로 이루어진다.
↓
SNS 환경에서는 정보 생성 주체가 개인이기 때문에 개인 중심의 자산가치와 발생 가능성을 반영한 위험도 산정 방법이 필요함.
2. 제안하는 개인정보 유출위험도 측정 방법
2.1 SNS에서의 개인정보 자산가치
개인을 식별할 수 있는 정도와 이를 악용하는 정도에 따라 위험 정도가 부여된다.
| 데이터 구분 | 자산 가치 | 내용 |
| 서비스 데이터 |
3~5 | 이름, 나이 등의 개인프로필에 해당하는 정보로 악용할 경우 위험이 매우 큰 정보와 신상정보가 추정 가능한 정보 포함 |
| 공개 데이터 |
1~5 | 자신의 페이지를 통해 게시한 정보에 해당한느 정보로 악용할 경우 위험이 매우 큰 정보에서부터 유출 시 민감한 정보 포함 |
| 행위 데이터 |
1~2 | 접근한 기사, 게임 등에 해당하는 정보로 신상정보를 파악하긴 어려워 유출 시 민감한 정보와 영향을 미치지 않는 정보 포함 |
2.2 개인정보 유출가능영역 설정
정보주체(개인)를 중심으로 친구(1차 영역), 친구의 친구(2차 영역) 등으로 점차 확장되는 구조를 가지며, 간선의 수에 따라 신뢰도나 유출 위험이 달라진다. 개인정보 유출가능영역은 1A(직접 친구)부터 시작해 여러 단계로 나뉘며, 각 영역에 접근한 인원 수와 거리(간선 수)에 따라 가중치를 부여한다.
2.3 위험도 평가
개인정보 유출 위험도 = 개인정보 노출률 x 개인정보 접근률 x 개인정보 자산가치별 가중치
영역별 가중치를 고려하여 신뢰도가 높은 1차 관계라도 안전하다고 가정하지 않으며 결과적으로 본인의 SNS 활동 패턴에 따라 유출 위험을 수치로 확인할 수 있다.
3. 성능평가
3.1 실험환경 및 인자 설정
- 사용자 수: 총 500명
- 소셜 네트워크 구조: 최대 5단계까지의 관계 영역 구성
- 컨텐츠 수: 50 ~ 1000개 사이 무작위 설정
- 노출된 개인정보 접근 수: 100 ~ 2000 사이 무작위 설정
- 실험은 개인정보 노출률과 접근률을 기반으로 위험도를 계산하는 방식으로 진행되었다.
| 시나리오 | 노출 패턴 | 접근 패턴 |
| 1 | 특정 개인정보에 노출 집중 | 특정 개인정보에 접근 집중 |
| 2 | 개인정보 균등하게 노출 | 접근 또한 균등 분포 |
시나리오1 결과:
1차영역에서 가장 위험도가 높게 측정됨 → 가까운 관계라고 해서 노출위험이 낮지 않다는 것을 의미
시나리오2 결과:
개인정보 노출과 접근이 균등하게 이루어진 경우 → 위험도는 자산가치와 노출률 접근률에 따라 고르게 분포
결론
SNS 환경에서 사용자가 스스로 개인정보 유출 위험을 인식하고 관리할 수 있도록, 정량적 위험도 측정 방법을 제안하였다. 개인정보를 자산가치별로 분류하고, 사용자의 관계망을 분석하여 영역별 유출위험도를 평가함으로써, 사용자는 자신의 정보가 어떤 경로로 유출될 수 있는지 구체적으로 파악할 수 있다. 본 연구 결과는 향후 SNS에서 개인정보 보호를 강화하는 보안 정책 수립에 실질적으로 기여할 수 있으며, 추가적으로 페이스북이나 트위터 같은 대규모 SNS 플랫폼에 적용하여 현실적인 위험 분석 연구로 확장할 필요가 있다.
배운점 및 느낀점
이번 논문을 통해 개인정보 유출 위험을 보다 체계적이고 구체적으로 평가할 수 있는 방법을 배울 수 있었다. 특히 SNS 환경에서는 개인정보 유출이 단순히 외부 공격에 의해서만 발생하는 것이 아니라, 사용자의 자발적 공개와 관계망을 통한 확산이 주요한 경로가 된다는 사실을 명확히 인식하게 되었다. 가까운 친구나 지인이라고 해서 개인정보가 안전하다고 단정할 수 없고, 관계의 거리, 개인정보 자산가치, 노출 빈도와 접근 빈도를 모두 종합적으로 고려해야 진정한 위험 수준을 알 수 있다는 점이 특히 인상깊었던 것 같다.
또한 SNS와 같이 복잡하고 유동적인 네트워크에서는 개인이 스스로 정보 노출을 통제할 수 있어야 하며, 이를 위해 객관적이고 수치화된 위험도 평가 지표가 반드시 필요하다는 것을 배웠다. 결국 개인정보 보호는 단순한 경고나 규제가 아니라, 구체적 데이터와 분석을 통한 사용자 인식 개선과 능동적 관리로 이어져야 하는 것 같다.
'논문 분석' 카테고리의 다른 글
| 다크웹 프로파일링을 위한 캡챠 분류 자동화 프레임워크 (0) | 2025.10.01 |
|---|---|
| 다언어LLM의 개인정보 보호 응답 불균형과 지역 기반 제어 정책 모델 제안 (0) | 2025.09.17 |
| 시스템 API 호출 순서정보를 통한 안드로이드 악성코드 패밀리 분류기법 (1) | 2025.05.28 |
| [논문분석]트래픽 분석을 통한 악성코드 감염PC 및 APT 공격탐지 방안 (0) | 2025.05.13 |
| [논문 분석] AI를 통한 BEC(Business Email Compromise) 공격의 효과적인 대응방안 연구 (0) | 2025.04.02 |